Content Promotion as a Strategic Game: How to Design Agentic Publishers for the Evolving Search Ecosystem in the GenAI Era?
With the rise of LLMs, publishers now operate in a dual world where traditional search and chat-like systems coexist. We propose a unified, game-theoretic view of this environment and highlight different tools, such as Multi-Agent Reinforcement Learning, that support the development of competitive content-optimization agents.
TL;DR
LLMs are transforming search from static ranked lists of results into interactive, chat-like experiences. LLMs also reshape the way publishers (i.e., content creators) generate content: they increasingly use LLMs and agentic tools to optimize rankings in traditional search and to improve their content visibility in the novel chat-like systems. Importantly, publishers engage in an iterative process: they observe how their content performs — whether it is highly ranked in the traditional search or visible in chat-like answers — and then strategically modify or regenerate their content in response to this feedback. As a result, the ecosystem becomes a strategic game with incomplete information, evolving feedback, and repeated interactions. In this strategic ecosystem, the publishers act as players striving to promote their content, competing for rankings and visibility under mechanisms that are only partially known to them. This blog outlines why game theory offers a natural framework to model these settings and to design agents acting on behalf of publishers. We highlight several frameworks such as Game theory and Multi-agent Reinforcement learning and show how they contribute to model and design effective agents. Our aim is to provide principled lens for content promotion in the LLM era.
LLMs Reshape Both Sides of the Search Ecosystem
Large language models have fundamentally reshaped the search experience
But the transformation is not limited to the user side of the ecosystem.
LLMs are also reshaping the publisher side. In the traditional Web era, publishers focused on keyword and hyperlink optimization, and content structure to influence ranking
- to generate or refine content;
- to adapt their content to the behavior of LLM-driven retrieval and QA systems;
- to strategically shape their content so that they are selected, quoted, or incorporated into the ranked list of results or the generated answer.
The paradigm of helping publishers in improving their content visibility in generative engine responses is often called Generative Engine Optimization (GEO)
Publisher Incentives Across Coexisting Ecosystems
The search ecosystem is not transitioning overnight — it is evolving. Today, publishers operate in a hybrid world where traditional search engines and LLM-driven chat interfaces coexist. Users still issue keyword queries and click ranked results, yet they also increasingly engage with conversational systems that generate responses. As a result, publishers must navigate two overlapping incentive structures at once.
Publishers’ Incentives in the Traditional Setting
In the traditional setting, publisher goals are well-defined and widely understood. Visibility depends on ranking, which in turn hinges on factors, some of which are familiar:
- content relevance;
- content quality and structure;
- signals (e.g., PageRank
).
Metrics such as impressions and CTR (Click Through Rate) offer interpretable objectives.
Publishers’ Incentives in the Chat-Like Settings
By contrast, the objectives in the chat-like settings are far less defined. Publishers know that visibility is tied to whether the chat-like setting:
- retrieves their content;
- cites or incorporates it into the generated response;
- and positions it prominently in the generated response.
But unlike in traditional search, where there is a clear notion of a ranked results page, LLM-based systems provide no public ranking, and often little transparency about how sources are selected for retrieval or attribution.
The publisher’s utility is therefore inherently vague: Is success defined by:
- citation count?
- contribution to the generated answer?
- similarity of the generated answer to the publisher’s content?
- some combination of the above?
The field has not yet converged on a clear success criterion, and the objective itself is still ill-defined, making strategic optimization an open problem.
Leveraging LLMs for Content Optimization
Publishers — or agents acting on behalf of them — can leverage LLMs as powerful content optimization tools (See Figures 1 and 2). The publishers are incentivized to have effective automatic generation to promote their content. However, any such agentic systems should be carefully designed:
- address the tradeoff between “content promotion” (e.g., being selected in the search results or being visible in the generated response) and “faithfulness” to the original intent (e.g., not deviating from the content before optimization);
- address the uncertainty about the ranker or the content selection/generation mechanism;
- address competing agents which aim to optimize contents of other stakeholders.


Content Promotion as a Game
We argue that game theory provides a major and essential framework for analyzing the resulting competitive dynamics and for designing agents that assist publishers to strategically promote their content. More precisely, repeated games with incomplete information
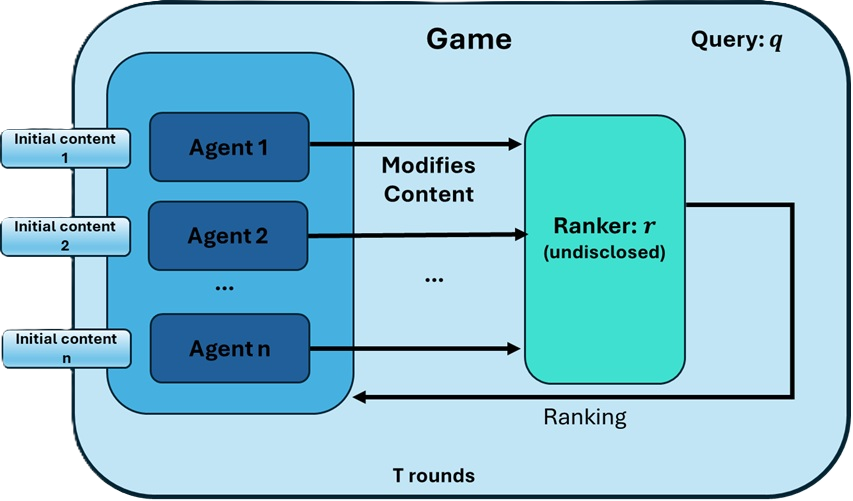
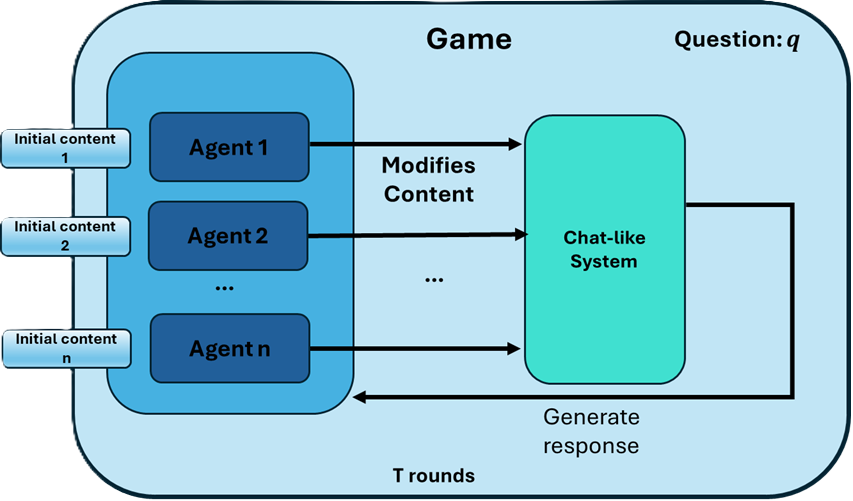
The viewpoint just presented is aligned with a growing body of research that treats content promotion as a strategic process. During recent years, several works have applied game-theoretic approaches to model competitive search
However, the technological transformation of the last few years — particularly the rise of LLM-based chat interfaces — calls for re-examination and adaptation of the assumptions in classical game theoretic models. Traditional work often assumes fixed ranking functions and explicit publishers’ incentives. In contrast, chat-like systems generate personalized and dynamic answers
Agent Design Aspects for Traditional Search and Chat-like Systems
We delve into three important aspects that should be considered when designing agents that assist publishers promote their content.
The first ingredient that can (and will) be naturally used, is to exploit the significant power of LLMs, e.g., use clever prompt engineering to promote content and maintain faithfulness in such games.
A second ingredient one should be aware of is incomplete information about the selection or generation mechanism applied by the system. Using, for example, information about the decision made by the mechanism (e.g., past responses) can help to train and fine tune agents.
The third ingredient is the need to be aware of competitors’ behavior. With limited access to annotated data — and only partial observability of the decisions made by these systems — this calls for carefully designed simulation tools. here again LLMs can be used as effective generative tools.
Heretofore, we have described content promotion as a publishers game, shaped by evolving search and chat-based ecosystems and by the increasing role of generative AI. We now discuss different frameworks that can be employed to model and design effective agents in such settings.
Frameworks
Multi-Agent Reinforcement Learning (MARL)
This framework models each player as an autonomous learning agent that optimizes its policy through repeated interaction with the environment and with other agents. MARL enables us to study how strategic behaviors emerge end-to-end from experience, without imposing strong assumptions about how these systems (i.e., search or chat-like systems) operate internally
(a) Short-term wins vs. long-term information leakage
An agent may be able to win an individual round of a game by aggressively optimizing its content. However, doing so may reveal its strategy to competing agents, enabling them to quickly imitate
(b) On-policy vs. off-policy training
A crucial design question is whether the agent should continue learning during the game (on-policy) or rely solely on offline training before the game begins (off-policy).
- Online adaptation allows the agent to track shifting competitor behaviors or evolving ranking/generation mechanisms.
- Offline training offers stability and avoids overfitting to short-term noise or adversarial manipulations. Choosing between online and offline modes — or combining them — depends on the environment’s stability, observability, and the computational budget during gameplay.
(c) Constructing the loss function
A core challenge is designing a loss function that balances ranking promotion or content visibility with faithfulness to the original content. On one hand, the agent should modify content to improve performance; on the other hand, excessive deviation risks harming credibility, violating constraints, or triggering penalties. The loss function must encode this balance explicitly — penalizing harmful drift while incentivizing strategic, beneficial content modifications.
Synthetic Dataset Generation
Sometimes real-world data presents substantial limitations: it may be inaccessible, noisy, incomplete, or simply ill-suited for the specific questions we wish to study. For this reason, we propose constructing synthetic datasets with controlled statistical properties. Synthetic data enables us to systematically probe targeted hypotheses — for example, how diversity constraints, noise structure, or shifts in the query or question distribution influence agent behavior and system-level outcomes. Moreover, synthetic datasets provide repeatability and experimental control that are often impossible with logs of production systems. They allow for clean ablation studies, controlled perturbations, and the isolation of causal factors, all of which are essential for understanding and improving agents operating in competitive ranking and chat-like ecosystems. Importantly LLMs now make it feasible to generate high-fidelity synthetic datasets at scale, enabling richer and more flexible experimental environments than were previously possible.
Simulation Environment
A simulation environment that models the rules of the game, the ranking or generation function, and the interaction protocol between agents is essential in the discussed strategic ecosystems
Self-Play
Self-play is a method for iteratively training agents to be improved by competing (via simulation) against evolving versions of themselves
Meta Games and Learning Equilibrium
Agent design itself introduces an additional strategic layer: designers may choose between different LLM architectures, training procedures, datasets, prompting strategies, or RL frameworks. In this broader perspective, agents are not only competing within a single ranking or generation game, but the designers are competing in a meta-game over agent designs
Instead, probabilistic ensembles of designs — mixtures over algorithms, prompting strategies, or training regimes — may provide better robustness and theoretical guarantees. These ensemble-based strategies reduce exploitability, adapt better to heterogeneous opponents, and align with classical results in game theory showing that mixed strategies often outperform pure ones in competitive environments.
Within meta-games over agent designs, a natural solution concept is learning equilibrium
This distinction is subtle but important: learning equilibrium ensures that agent designs collectively converge to a stable distribution, even as the content-generation game continues to evolve. Such a concept becomes particularly relevant in scenarios where a platform or cloud provider offers content-generation services to multiple competing parties. In this setting, providing agent designs that satisfy learning equilibrium naturally mitigates exploitability, promotes fairness, and guarantees robust performance across heterogeneous competitors.
Preliminary Results
We now turn to discuss several papers that illustrate components (or the absence thereof) of the frameworks discussed above.
Prompt-based Agent
RLRF-based Agent
LEMSS
Attacking RAG-based systems
Recent work highlights the growing vulnerability of retrieval-augmented generation (RAG) systems to targeted manipulation. PoisonedRAG
Tools
Designing agents for ranking and content promotion competition benefits from a growing ecosystem of LLM-oriented development tools. Copilot Studio, Vertex AI, and LangChain provide the infrastructure needed to orchestrate complex LLM workflows, connect models to external data, and manage iterative agent-environment interactions. Copilot Studio enables rapid prototyping of agent behaviors within controlled interfaces, while Vertex AI offers scalable model hosting, fine-tuning, and evaluation pipelines suited for experimentation at scale. LangChain adds modular abstractions — such as memory, tools, retrieval, and multi- step reasoning — that make it easier to construct agents capable of interacting with dynamic environments. In addition, there are many python packages that may help to design and simulate RL-based agents such as
Conclusion
In this blog post, we discussed how LLMs are reshaping the search ecosystem — both in traditional search and in emerging chat-like question-answering systems. Beyond transforming how users search, LLMs also change how publishers operate, enabling them to leverage LLMs to strategically optimize and promote iteratively their content.
We discussed several frameworks for modelling and designing such agents, including game- theoretic models and reinforcement learning approaches. These frameworks help account for multiple layers of uncertainty: the opaque ranking model or response-generation mechanisms of retrieval systems, the dynamic nature of evolving user queries/questions, and the competitive behavior of other strategic publishers or human content creators.
To build robust and adaptable agents, we emphasized that simulation plays a crucial role. Simulations enable the creation of strategic synthetic datasets and provide controlled environments for evaluating agent behavior, stress-testing policy robustness, and studying long-term dynamics in repeated competitive scenarios.
Overall, as the ecosystem continues to evolve, combining insights from game theory, reinforcement learning, and simulation offers a principled path toward designing agents capable of succeeding in both current and future search paradigms.